Comprendre le Waterfall en Finance : Répartition des Gains et Stratégies d’Optimisation. Un article GOWeeZ pour vous expliquer Le waterfall, ou cascade de distribution. Ce mécanisme est clé en finance,
La Génération Assistée par Récupération ou Retrieval-Augmented Generation (RAG) est une méthode sophistiquée pour rendre les Larges Modèles de Langage (LLM) encore plus efficaces.
Ces modèles sont comme des super-cerveaux formés sur une tonne de données. C’est donc un modèle de données boosté par un super algorithme. Il est gonflé aux testostérones pour accomplir des tas de tâches, comme répondre à des questions ou traduire des langues.
Eh bien, imaginez que ces super-cerveaux sont comme des bibliothèques géantes. Ils ont déjà beaucoup de connaissances accumulées. Mais parfois, ils ont besoin de consulter d’autres sources pour être vraiment précis. C’est là que la RAG entre en jeu.
Ces supers modèles et algo vérifient des informations dans d’autres bibliothèques de confiance avant de donner une réponse. Cela signifie qu’ils peuvent être encore plus utiles dans différentes situations sans avoir besoin d’être ré-entraînés.
La RAG est comme une mise à niveau intelligente pour ces super-cerveaux. Elle leur permet de rester au top de leur jeu, en fournissant des réponses pertinentes et précises, peu importe le contexte. Et le meilleur dans tout ça ? C’est une façon efficace d’améliorer ces super-cerveaux sans dépenser trop d’argent ou de temps à les ré-entraîner.
Avec la RAG, nous avons un outil puissant qui permet aux LLM d’être encore meilleurs grâce à ces sources de connaissances fiables. Cela les rend plus précis, plus pertinents et plus utiles dans toutes sortes de situations.
Les Larges Modèles de langage (LLM) sont les pierres angulaires de l’intelligence artificielle (IA) générative. Elles propulsent les chatbots intelligents et autres applications de traitement du langage naturel (NLP). Leur mission est de répondre aux questions des utilisateurs dans divers contextes en puisant dans des sources de connaissances dignes de confiance. Mais voilà, des défis sont présents.
En effet, parfois les LLM peuvent donner des réponses imprévisibles, voire fausses, et leurs données d’entraînement ont une date de péremption.
Ainsi, leurs connaissances sont parfois obsolètes. Imaginez un collaborateur ou collègue plein d’énergie qui ne se met jamais à jour sur les événements actuels. Il donnerait des réponses trop génériques ou dépassées avec une assurance trompeuse.
C’est exactement cela ! La confiance des utilisateurs est tailladée, c’est l’effet pervers dont vos chatbots pâtissent.
C’est là que la RAG ou Génération Assistée par Récupération entre en jeu. Elle guide les LLM pour récupérer des infos pertinentes à partir de sources de confiance prédéfinies généralement extérieures.
Ainsi, on obtient un meilleur contrôle sur les réponses générées. La RAG est un atout crucial pour améliorer la fiabilité et la pertinence des réponses des LLM.

Prenons l’exemple du chatbot !
Développer un chatbot commence souvent avec un modèle de base, mais ajuster ces modèles aux besoins spécifiques de l’organisation peut coûter cher.
La technologie RAG offre une alternative rentable en introduisant de nouvelles données dans les modèles de langage, rendant ainsi l’IA générative plus accessible financièrement et techniquement pour les sociétés. Cela permet :
Garder les données de formation des modèles de langage à jour est un défi. Avec RAG, les développeurs peuvent fournir en temps réel les dernières recherches ou actualités directement au modèle. En se connectant à des flux d’actualités, le modèle peut rester constamment informé et fournir des réponses basées sur des données récentes.
Grâce à RAG, les modèles peuvent attribuer leurs sources, renforçant ainsi la confiance des utilisateurs. Les références aux sources, les citations peuvent être incluses dans les réponses. Ainsi, les utilisateurs peuvent consulter les sources originales pour plus de clarté. Cela renforce donc la crédibilité de l’IA générative.
Avec la RAG, les développeurs ont un contrôle total sur les sources d’information du modèle. Ils peuvent les ajuster selon les besoins et s’assurer que le modèle génère des réponses appropriées. De plus, dépanner et corriger les références incorrectes devient plus facile, assurant ainsi une utilisation plus sûre et fiable de l’IA générative.
Autres éléments non négligeables :
Les données nouvellement acquises, en dehors de l’ensemble de données initial du LLM, sont désignées comme des données externes. Elles peuvent être obtenues auprès de diverses sources telles que des API, des bases de données ou des référentiels de documents fournis par des prestataires de données. Ces données se présentent sous divers formats, comme des fichiers, des enregistrements de bases de données ou des textes longs.
Elle convertit les données en représentations numériques stockées dans une base de données vectorielle.
Par exemple, cela permet la construction de Knowledge Graph, (voir l’article sur Neo4j), En effet, en couplant une Base de Données graph avec un LLM on obtient un modèle efficient.
En effet, Neo4j annonçait en aout 2023, son engagement dans le domaine de l’IA générative en introduisant son nouvel outil Native Vector Search pour ses bases de données de graphes. Cette fonctionnalité permet aux entreprises de mener des recherches sémantiques avancées et agit comme une mémoire à long terme pour les Larges Modèles de Langage (LLMs), tout en minimisant les erreurs.
Ainsi, une banque de connaissances accessible aux modèles d’IA générative est proposée.
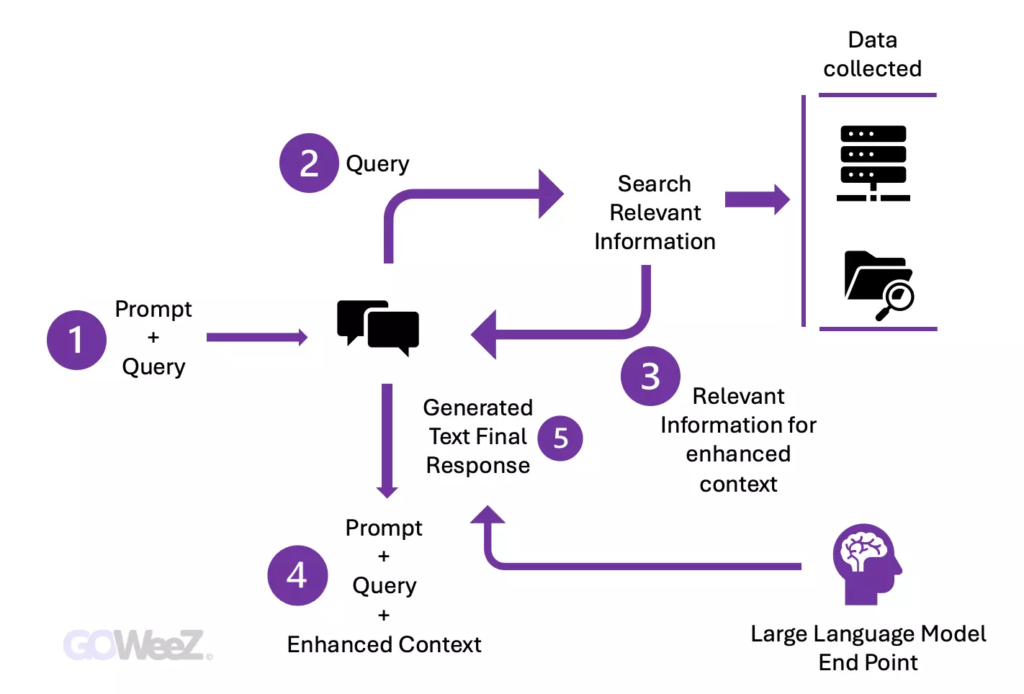
Ensuite, une étape cruciale intervient : la recherche de pertinence. Lorsqu’un utilisateur formule une requête, celle-ci est transformée en une représentation vectorielle et confrontée aux bases de données vectorielles.
Prenons l’exemple d’un chatbot intelligent spécialisé dans les questions liées aux ressources humaines d’une entreprise. Si un employé demande « Combien de jours de congés annuels me reste-t-il ? », le système ira chercher les documents concernant la politique en matière de congés annuels, ainsi que l’historique des congés de l’employé. Ces documents précis seront renvoyés car ils correspondent étroitement à la demande de l’employé.
Ainsi, la pertinence est calculée et établie à l’aide de calculs et de représentations mathématiques vectorielles.
Par la suite, le modèle RAG complète l’entrée de l’utilisateur (ou les messages-guides) en ajoutant les données pertinentes extraites dans le contexte.
Cette étape utilise des techniques d’ingénierie de l’invite pour communiquer efficacement avec le LLM. L’invite augmentée permet aux grands modèles de langage de générer une réponse précise aux requêtes de l’utilisateur.
Vous vous demandez peut-être : que se passe-t-il si les données externes deviennent obsolètes ? Pour maintenir des informations fraîches pour vos recherches, il est important de mettre à jour les documents de manière régulière et asynchrone.
Cela peut se faire de différentes façons : soit en automatisant le processus pour qu’il se fasse en temps réel, soit en effectuant des mises à jour périodiques en lot. C’est un problème fréquent dans le domaine de l’analyse de données, mais il existe des approches basées sur la science des données pour gérer ces changements.
La recherche sémantique booste la RAG pour intégrer efficacement des connaissances externes dans les applis LLM.
Par conséquent, avec les entreprises stockant de plus en plus de data dans divers systèmes, la recherche traditionnelle peine à fournir des résultats génératifs de qualité précise.
En réponse à cela, la recherche sémantique plonge dans cette mer d’infos, extrayant précisément ce dont on a besoin.
Par exemple, répondre à des questions comme les dépenses de réparation l’an passé en reliant la requête à des docs pertinents, garantissant une réponse spécifique plutôt qu’une simple liste de résultats de recherche.
Ainsi, par opposition aux méthodes classiques qui limitent les résultats pour les tâches complexes, la recherche sémantique prend en charge la préparation des données, générant des extraits et des mots clés pertinents pour enrichir les applications LLM.
Nous vous invitons pour en savoir plus sur ces nouvelles possibilités de lire cet article sur le blog du webmaster






