The French startup ecosystem continues to create jobs, with 4% growth in the first half of 2024. While hiring remains strong (+17%), a rise in layoffs in June calls for
Retrieval-Augmented Generation (RAG) is a sophisticated method for making Large Language Models (LLMs) even more efficient.
These models are like super-brains trained on a ton of data. So it’s a data model boosted by a super algorithm. It’s pumped up on testosterone to do all sorts of tasks, like answering questions or translating languages.
Well, imagine that these super-brains are like giant libraries. They already have a lot of accumulated knowledge. But sometimes they need to consult other sources to be really precise. That’s where AGR comes in.
These super models and algo’s check information in other trusted libraries before giving an answer. This means they can be even more useful in different situations without needing to be re-trained.
RAG is like an intelligent upgrade for these super-brains. It allows them to stay at the top of their game, providing relevant and accurate answers, whatever the context. And the best part? It’s an effective way of improving these super-brains without spending too much money or time re-training them.
With RAG, we have a powerful tool that allows LLMs to be even better thanks to these reliable sources of knowledge. It makes them more accurate, more relevant and more useful in all kinds of situations.
Large Language Models (LLMs) are the cornerstones of generative artificial intelligence (AI). They power intelligent chatbots and other natural language processing (NLP) applications. Their mission is to answer users’ questions in a variety of contexts by drawing on trusted sources of knowledge. But there are challenges.
LLMs can sometimes give unpredictable or even wrong answers, and their training data has an expiry date.
As a result, their knowledge is sometimes obsolete. Imagine an energetic colleague who never keeps up to date with current events. He would give answers that are too generic or out of date, with a deceptive confidence.
This is exactly what happens! User trust is slashed, and that’s the perverse effect your chatbots suffer from.
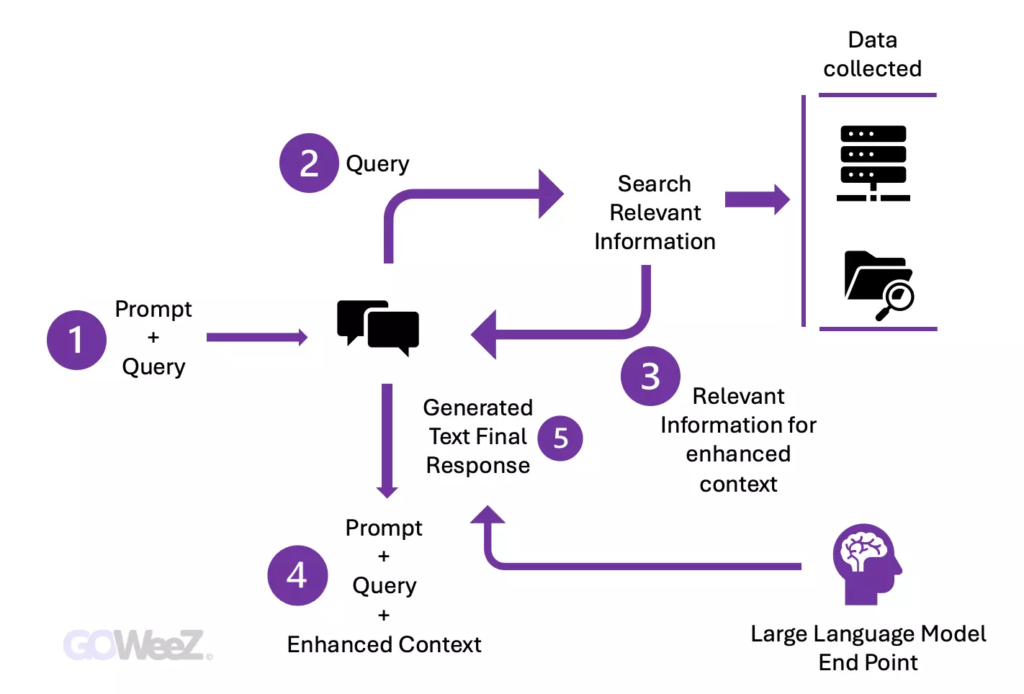
This is where RAG or Recovery-Assisted Generation comes in. It guides LLMs to retrieve relevant information from predefined trusted sources, usually external.
Ainsi, on obtient un meilleur contrôle sur les réponses générées. La RAG est un atout crucial pour améliorer la fiabilité et la pertinence des réponses des LLM.
Take chatbots, for example!
Developing a chatbot often starts with a basic model, but adjusting these models to the specific needs of the organisation can be expensive.
RAG technology offers a cost-effective alternative by introducing new data into language models, making generative AI more financially and technically accessible for companies. This enables:
Keeping language model training data up to date is a challenge. With RAG, developers can provide the latest research or news directly to the model in real time. By connecting to news feeds, the model can stay constantly informed and provide answers based on recent data.
Thanks to RAG, models can attribute their sources, reinforcing user confidence. References to sources and quotations can be included in responses. In this way, users can consult the original sources for greater clarity. This strengthens the credibility of generative AI..
With RAG, developers have total control over the sources of information in the model. They can adjust them as required and ensure that the model generates appropriate responses. In addition, troubleshooting and correcting incorrect references becomes easier, ensuring safer and more reliable use of generative AI.
Other significant factors :
Newly acquired data, outside of the initial LLM dataset, is referred to as external data. It can be obtained from a variety of sources such as APIs, databases or document repositories provided by data providers. This data comes in a variety of formats, such as files, database records or long text.
It converts data into digital representations stored in a vector database..
For example, this enables the construction of Knowledge Graphs, (see the article on Neo4j), Coupling a graph database with an LLM produces an efficient model.
In fact, In August 2023, Neo4j announced its commitment to generative AI by introducing its new Native Vector Search tool for its graph databases. This feature enables companies to conduct advanced semantic searches and acts as a long-term memory for Large Language Models (LLMs), while minimising errors.
The result is a knowledge bank accessible to generative AI models.
Next comes a crucial stage: relevance research. When a user formulates a query, it is transformed into a vector representation and compared with vector databases.
Let’s take the example of an intelligent chatbot specialising in human resources issues for a company. If an employee asks ‘How many days of annual leave do I have left?’, the system will fetch documents relating to the annual leave policy, as well as the employee’s leave history. These specific documents will be returned because they closely match the employee’s request.
In this way, relevance is calculated and established using calculations and mathematical vector representations.
Subsequently, the RAG model complements the user input (or prompts) by adding relevant data extracted from the context.
This step uses prompt engineering techniques to communicate effectively with the LLM. Augmented prompting enables large language models to generate an accurate response to user queries.
You may be wondering: what happens if external data becomes obsolete? To maintain fresh information for your research, it is important to update documents regularly and asynchronously.
This can be done in different ways: either by automating the process so that it happens in real time, or by carrying out periodic batch updates. This is a common problem in data analysis, but there are data science approaches to managing these changes.
Semantic search boosts RAG to effectively integrate external knowledge into LLM applications.
As a result, with companies storing more and more data in various systems, traditional search is struggling to provide generative results of precise quality.
In response, semantic search dives into this sea of information, extracting precisely what is needed.
For example, answering questions like how much was spent on repairs last year by linking the query to relevant documents, guaranteeing a specific answer rather than a simple list of search results.
So, as opposed to traditional methods that limit results for complex tasks, semantic search takes charge of data preparation, generating extracts and relevant keywords to enrich LLM applications.
To find out more about these new possibilities, we invite you to read this article (in french) on le blog du webmaster






